

Abiogenesis Exposed Series #2: Did Life Originate by Chance? Necessity? or Design?
- Jason Pluebell
- Jun 24, 2025
- 46 min read

Updated: Jun 24, 2025
In the first article of the Abiogenesis Exposed Series, we got a very general view of what Abiogenesis is and the basic macromolecules needed for life: (https://www.ptequestionstoeden.com/post/abiogenesis-series-exposed-1-what-is-abiogenesis). For review, abiogenesis is the scientific theory about how life is formed from non-living, prebiotic (before life) molecules. Abiogenesis is before the theory of biological evolution can occur, i.e., how life changes once it is started. Abiogenesis poses a different type of evolution called Chemical Evolution, which posits that simpler molecules slowly combined into more complex macromolecules that eventually formed the first living cells, and thus life.
Getting Things Straight
I will include this statement once again for the clarity of any new readers. My goal here is not to challenge the theory of biological evolution, i.e., the theory of how life changes once it is started. I aim to understand life; how the molecules that are not alive moved towards life by the manipulation of the natural laws that govern their interaction. Here’s the catch, though, before I even touch the topic of evolution’s validity; to get life-changing, you need to get it started, so the theory of abiogenesis is prior in sequence to the theory of biological evolution. Evolution's limitations are for another series, so here, we stick with whether an intelligent agent played a role in the origin of life, or if the chance/necessity of chemical evolution is responsible.
What is Life?
Before we even attempt to describe what is required for the simplest living organism to form (a cell), we must have some understanding of what it means to be alive. Science does not provide us with a clear and concise definition of what “life” exactly is; when a cell dies, we have no idea what we have lost exectly. What science can provide is a description of the characteristics that differentiate living systems from non-living matter. All living organisms must:
Be composed of cells. This includes multicelled life forms like a frog, and single-celled life forms like bacteria. We are composed of small cells.
Reproduce offspring. In life, there are two methods of reproduction: Asexual and Sexual reproduction. Can you guess which reproduction category we fall under?
Living things must increase in size and complexity over time, or simply grow and mature.
All living things must respond to stimuli, or changes in the environment, such as a change of light or temperature.
All living systems must carry out and perform chemical reactions that result in a gain of energy known as metabolism. (An example is the chemical reactions that break down the pancakes you had this morning into usable energy for your body.)
They must adapt to their environment through each generation reproduced by passing on inherited genetic traits.
All living systems must maintain a stable internal environment despite the external world constantly changing: Homeostasis.
These seven criteria for life are the very reason that the simple claim that Abiogenesis doesn’t require all these macromolecules to form together is fallacious. You need all the basic polymers in place and functioning for all seven requirements to be met. The leading hypothesis, the “RNA World Hypothesis,” posits that, since life cannot begin by chance of random assemblage, life was preceded by self-replicating RNA molecules. The problem with this is that an RNA molecule alone is not “life”, viruses use single-strand RNA, but even they must use biological systems (their host) to replicate their genomes and are not classified as living. We will also see the difficulties with forming an RNA nucleotide later; moreover, there must be information present before the formation of these molecules.
Isomeric, Enantiomeric, and Chiral Diversity of Each Molecule
Polymerize: combine a monomer into a polymer.
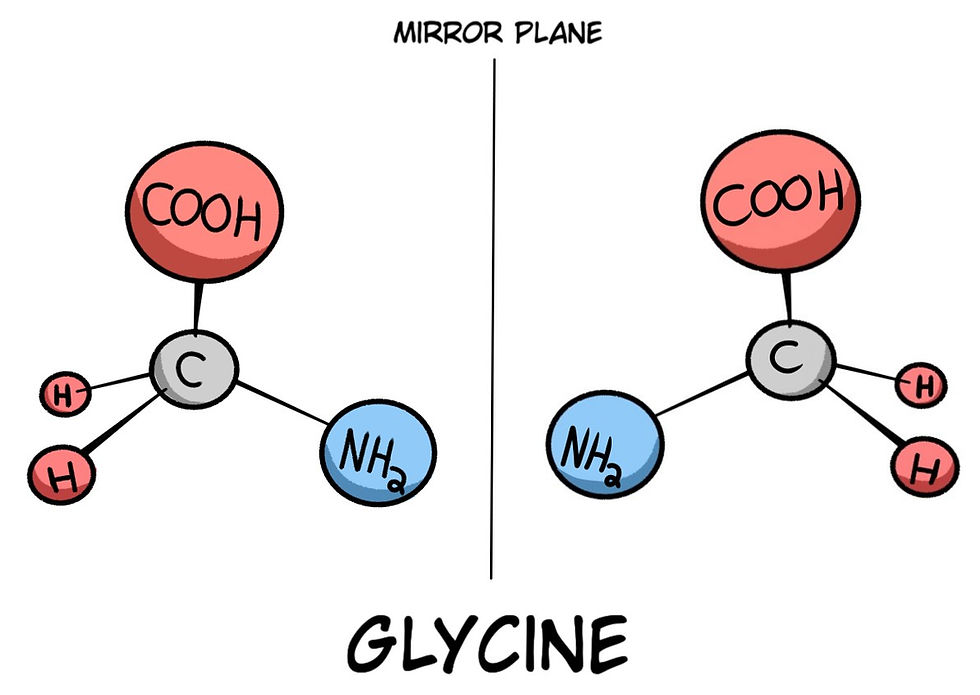
As mentioned in the previous article, each molecule has a mirror image of its atomic structure. Some of these mirror images are congruent, meaning their structures can be superimposed on one another when all the atoms are lined up.
A good example of some large-scale superimposable and non-superimposable objects is shown below (Fig. 2):
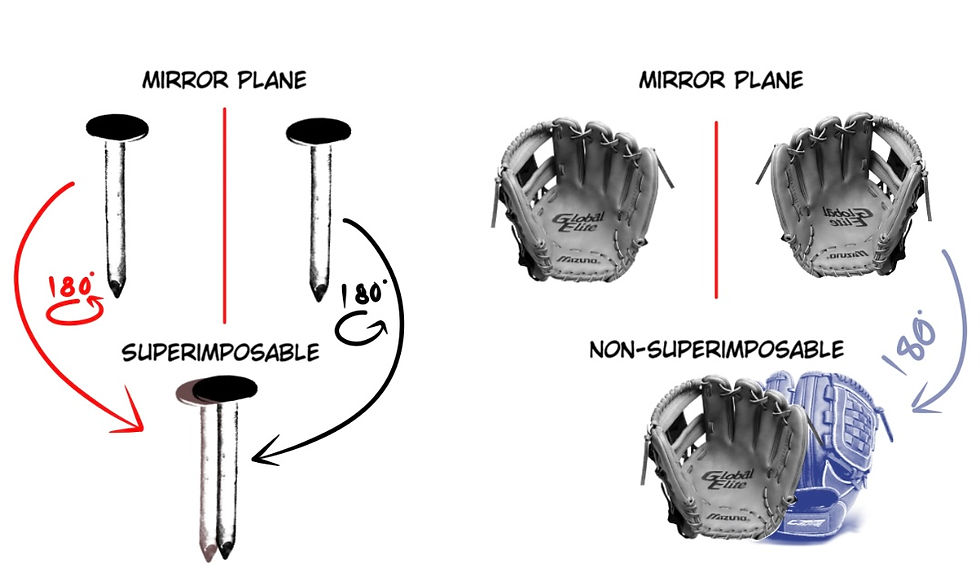
Some molecules’ mirror images are not able to be superimposed on one another (Fig. 3), and thus, in a biological scenario, only one specific handedness could be life-friendly. The issue is that natural reactions generate both chiralities of molecules. Chirality is the term used for the left and right-handed constructions of these molecules. Most of the biomolecules used in life are like this; they have chirality, but only one specific handedness is usable, which makes natural (and even synthetic) formation and polymerization extremely hard, even for chemists, because they have non-superimposable forms of chirality.
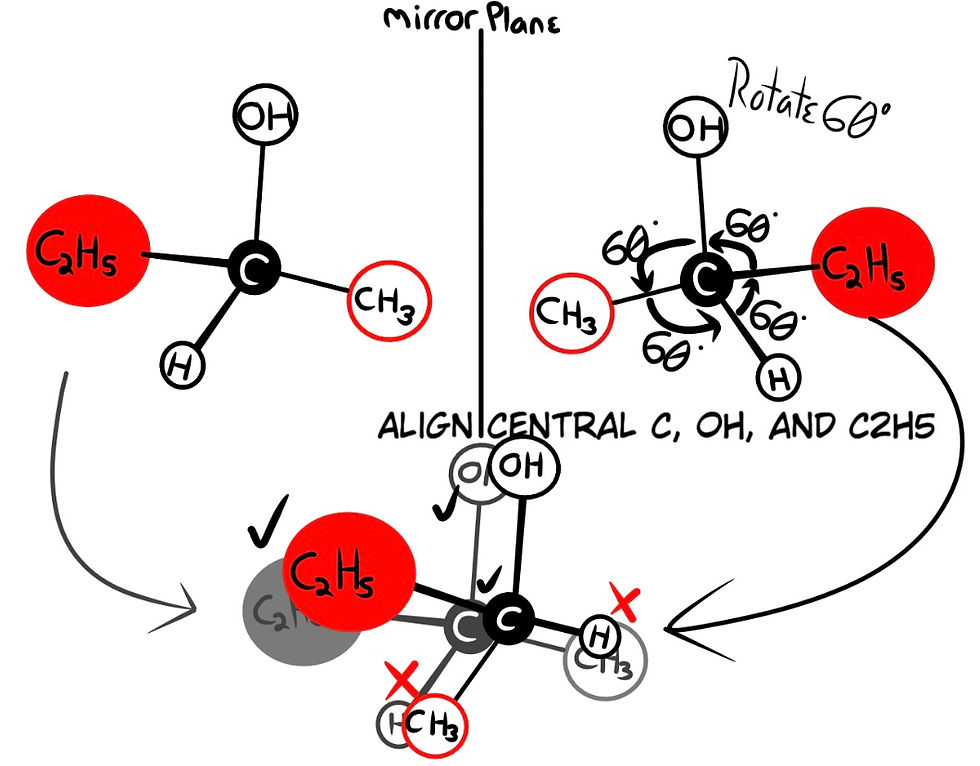
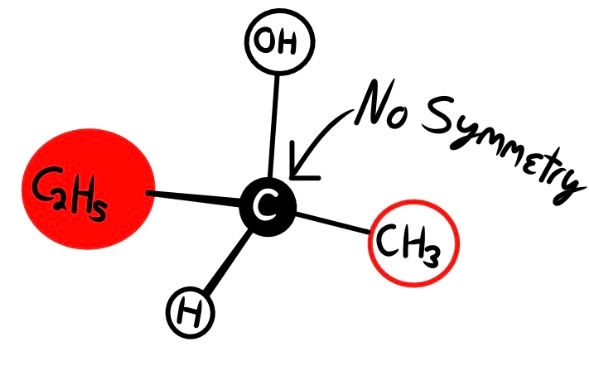
In the drawing above, a molecule called 2-butanol is displayed. If we align the central carbon, the above OH group, and rear C2H5, the molecules are non-superimposable due to their spatial configuration. Despite their molecular formula (number and types of atoms) being the same, the spatial arrangement of these atoms determines different chemical properties. Molecules that are not congruent to their mirror images are called Enantiomers. Enantiomers are chiral, meaning that only one handedness is usable to life. Molecules that are congruent and thus superimposable are called Achiral.
Synthesizing these types of molecules is extremely difficult for chemists today, which is why they use high-tech machinery and complex methods to create them, even then with moderate success.
Many chiral molecules contain one or more asymmetric central carbons (recall the center carbon of 2-butanol; the structures are asymmetric, see Fig. 4), called Stereogenic Centers. To save time, I will refer to these as stereocenters (Fig. 4).
Stereo-center/Stereogenic Center: Carbon atom with four groups bonded to it.
Isomer: Multiple spatial arrangements (compounds) with the same molecular formula (number and types of atoms) but different physical arrangements that lead to different chemical and physical properties.
Most chiral molecules contain one or more stereocenters, which means there's more complexity here. Do you think that 2 possible mirror constructions of each molecule are enough? Well, each stereo-center means there are more possible spatial constructions of the molecule. Up to 2n possible isomers can occur, where the exponent (n) represents the total number of stereocenters. Shown below is an example taken from Dr. Tours' Abiogenesis series on YouTube (https://www.youtube.com/playlist?list=PLILWudw_84t2THBvJZFyuLA0qvxwrIBDr) to display the above concept of isomers.
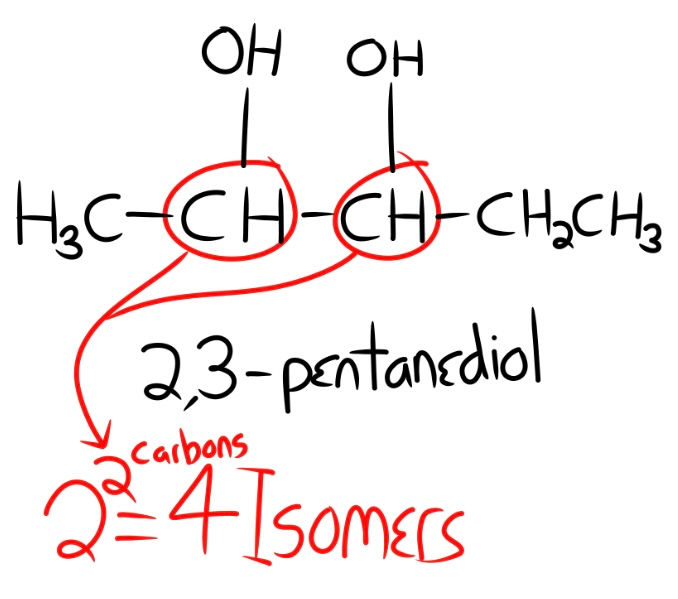
Shown above is the molecule 2,3-pentanediol, a research chemical used in preparing oxidation crystallization, also has possible food applications and antifungal properties, and is used in the production of plastic. 2,3-p has two stereocenters, which means 2x2, or 4 possible isomers. The more stereo-centers, the more possible isomers, and some biomolecules have thousands of isomers that can naturally form, a level of complexity that abiogenesis researchers cannot hurdle.
Not only does each molecule contain a mirror image of itself, but also each construction has many possible isomers that can naturally form. Each one of these molecules has multiple unprotected reaction sites that will compete for connection when polymerization happens. In other words, each molecule has many points of connection that, when forming a polymer, will all be open to random connections, which can result in the incorrect sequence and linkage of monomers. Think of a 4x4 LEGO brick: your goal is to connect them into a long pole to use as a flagpole on your LEGO house. Each brick has 4 possible buds to click in place; all 4 buds must connect to the next brick to make a straight flagpole. Say you connect them all by 2 buds each, is your flagpole straight? No, and it doesn’t even resemble a flagpole (See Fig. 6).
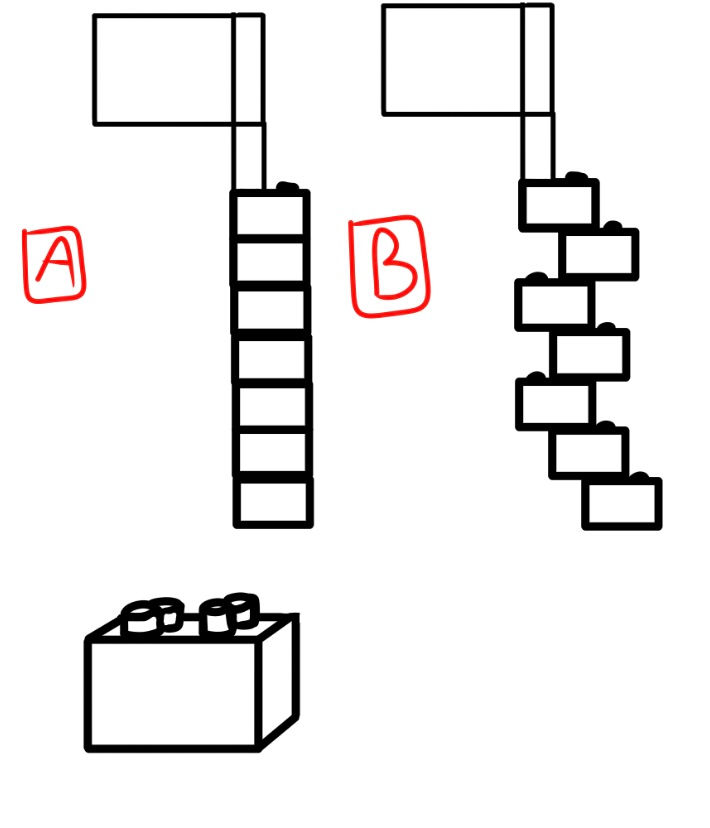
In the same sort of way, this applies to the polymerization of molecules. Now, these chiral molecules, called enantiomers, must have one more condition in a prebiotic scenario for life-friendly polymerization to happen. The molecules must be Homochiral, meaning they must be present in 100% enantiomeric excess. A simpler explanation is that these molecules must be present in 100% one-handedness at the location of synthesis and polymerization for life-friendly synthesis to even be considered possible. If there is any contamination of a different handedness/chirality, then the different molecules will interact with each other and cause unwanted branching, resulting in a useless mixture called asphalt. This is a condition that is left out of mainstream research, and it is mainly for this reason that most papers do not actually meet the mark of a plausible synthesis of these molecules and their polymers.
The reason that this issue is not a problem for a living organism is that we have enzymes that can control reactions and filter out the incorrect handedness. This is why you can eat a hot dog, take some Advil, vitamins, and maybe a steroid for your achilles tendonitis, and your body will be completely fine with the mix of chemicals. Your highly complex biological systems can isolate the various compounds.
The Synthesis and Correct Concentration of Polymers
If we regress the steps of acquiring the first cells back to the start, the essential materials for life must form via a natural cause. Just like how a house, before it begins, must have raw material from the finished products that are required to build the house. For example, a tree must be cut down, transported to a sawmill, cut into planks, then be pressure-treated if necessary, and then let out to dry before being shipped to the house's work site to be cut down into smaller planks and nailed into studs. Here, the raw material (the tree) went through a process (sawmill) where it was transformed into the finished product (wooden plank) to be used in a larger project, where other products are combined to construct a complex system of walls, pipes, wires, concrete, bricks, sand, other devices and insulation called a house.
Just like any building project, life must begin with raw materials that must form larger materials to combine into a more complex project called a cell. Many scientists researching the origins of life conduct reactions that produce a product under specific conditions. Change Laura Tan and Rob Stadler in their book “The Stairway to Life” lay out a good way of explaining this. Many describe chemical reactions like A + B = product C under conditions D, E, F, and so on. For example, C is formed under the conditions of no oxygen present (D), A constant temperature (E), and a present acting catalyst (F).
Catalyst: A substance that accelerates a chemical reaction without being altered by the reaction or consumed in the products.
Racemic/Racemate: A mixture of both left and right-handed molecules.
Solvent: A substance that is capable of dissolving another substance to form a solution. A good example is water dissolving salt to form a saltwater solution.
Yield: The resulting products of a reaction.
Almost all experiments begin with a highly purified concentration of starting materials A and B purchased from laboratories that either synthesize or isolate the materials from a biological source using highly specified lab technology. These manufacturers either isolate the monomers from already existing life’s polymers and rebind them into other polymers, or isolate the monomers to be reasssembled by a chemist later. The issue here is that natural forces can’t contact these laboratories to purchase the highly purified mixture from life on a pre-life Earth. Natural reactions, void of a chemist, always create a racemic mixture of molecules. Recall earlier, and in the last article, how I explained that some molecules have a characteristic of right and left-handed constructions called chirality. A racemic mixture is a mix of both left and right-handed arrangements. In a natural scenario, say a chemical reaction randomly occurs and produces some ribose (the sugar used in the RNA molecule), the reaction would produce a racemic mix of ribose (and all of its isomers), and these different handednesses would interact with each other to form long branching chains that are completely useless to life (the specific handedness must be in 100% purity, called Homochirality).
The British Chemist and Abiogenesis advocate Leslie Orgel has set up a list of requirements for a researcher to claim possible “prebiotic synthesis” (Orgel, L. E., Prebiotic chemistry and the origin of the RNA world. Critical Reviews in Biochemistry and Molecular Biology, 2004. 39(2), Pg 99-123.). Prebiotic synthesis refers to the act of creating/forming the necessary molecules in a prebiotic fashion, or in other words, through purely natural causes. Note that there is little agreement on what prebiotic conditions were actually like (Where did it happen? What were the gases or materials present? What is the right temperature range? These are discussed later.), and whose experimental conditions are the most “prebiotic”. Leslie’s requirements are paraphrased in the following:
It must be plausible, at least to the researchers, that the starting materials could be present and in the correct amounts in a prebiotic environment.
Synthesis MUST occur in water or in the absence of a solvent.
The yields must be significant, at least to the observers.
Notice how the validity of plausibility and yields are completely subjective to the researchers in the first and last requirements. This helps explain why so many papers meet the criteria for “prebiotic synthesis” despite their conditions, requirements, and limitations, saying otherwise. The focus is nowhere near presenting an actual natural cause that produces these molecules in 100% purity at the synthesis site, although the intent may be. This subjectiveness allows for the excitement to create the false hope that any yields are plausible and valid, and thus the laymen believe the researcher's claims without having the expertise to examine their work and point out their obviously troubling limitations.
These requirements will be taken into account when we go over the research results in a later article. Below includes a section on the requirements for the formation and synthesis of each biomonomer and its polymer, and then a walk-through of some chance calculations of the formation and polymerization of one specific type of each. The catch here is that Homochirality and some other assumptions are given for the calculations; despite this advantage, the results are not in favor of Abiogenesis's validity and thus must be accepted on pure faith. By ruling out mathematical chance as a meaningful factor in the issue, you unreasonably deny applicable calculations and accept the validity of the theory on blind faith.
Amino Acids (Proteins)
Amino Acids are the building blocks of proteins. On their own, they are known as monomers, and I refer you to the previous article where we covered how monomers (simple molecules) combine to form chains called polymers (larger molecules made from simpler molecules). The main method of sythesizing amino acids in labs is through a series of condesation reactions that must be performed in water (they are claimed to be done in water because they create a hydrophobic pocket where no water is present for the reactions, but the pocket being submerged in water is acclaimed as the reaction being perfoermed in water, which is a very biased and dishonest presentation of the results). The issue here is that these reactions generate water, which, in a prebiotic scenario, in water, would disrupt the equilibrium of the reaction site and products to an undesirable and irrelevant state. Moreover, water inhibits the polymerization of a lot of molecules. When the results of these experiments are discussed, more than enough speculation is applied to their implications for prebiotic relevancy.
Amino acids contain two main sub-parts, an amino group (H2N) and a carboxylic acid group (COOH). Amino acids can be zwitterions where two opposite charged parts (+ and -) embody the same molecule; this will be explained later. There are beta and alpha amino acids, where life uses primarily alpha. The difference is in their molecular structure; α-amino acids have their amino group bonded to the α-carbon (center CH) to the carboxylic acid (COOH).

Many amino acids can bond together via a peptide bond (Fig. 8). When more than one amino acid is bonded to another, they are known as peptides. Many peptides can link together to form proteins, and many protein complexes can fold together to form enzymes. Proteins are very large peptides.
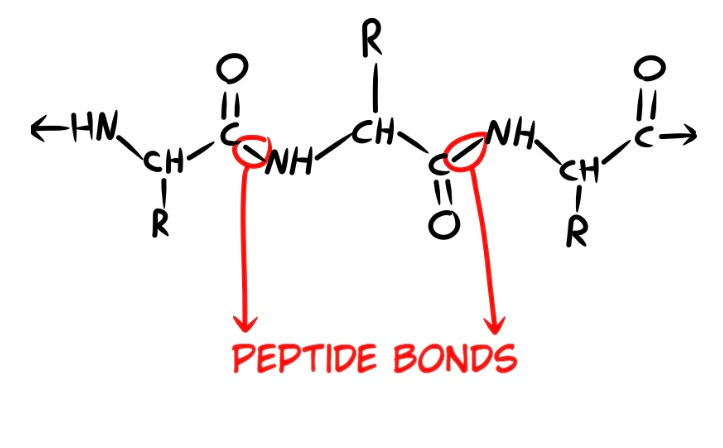
There are 20 naturally occurring amino acids found in life, and Abiogenesis researchers must present a synthesis for all 20. In the drawing above, the branches (labeled R) must be protected because if they are not, they will participate in binding and form random undesired branches. All amino acids, except glycine, contain stereocenters and are thus chiral. This means that there is a lot of homochirality to deal with here. Another big issue is that nobody has performed even this, not one experiment producing the right concentration of homochiral amino acids. The Miller-Urey experiments produced racemic mixtures, and the most modern versions of these only produce 11 out of the 20 types. The unfortunate reality is that most scientists don't believe that life originated in the atmosphere anyway, like the Miller-Urey experiment assumed, so this path has ended.
Hydrolysis: Breaking down a compound via reactions performed with water.
Ion-exchange Chromatography: Separating molecules by taking advantage of the different net charges/ acidic properties.
Moving on to molecular manufacturers, peptides can be hydrolyzed to their amino acid monomers in hydrochloric acid. Enzymes are also used (taken from already existing biological systems) to break apart the peptide bonds inside laboratories. Ion-exchange chromatography is used to separate amino acids from a mixture of other forms and chiralities by passing the mix through a cation-exchange resin, where the different charges will group with the same charge and pass through the resin in concentrated bands and be extracted.
Remember that in every single origin of life experiment performed, the peptides used came from nature, I.E., biological systems. And when they perform the peptide bonding, they use man-made molecules to correctly form peptide bonds and protect the branches mentioned earlier. Let's chew on this for a few... this means that there are no prebiotic forces present that can create or bond amino acids. You are left to pure blind chance at that point.
Once a peptide is formed in a cell, its chain structure can exist in two forms:
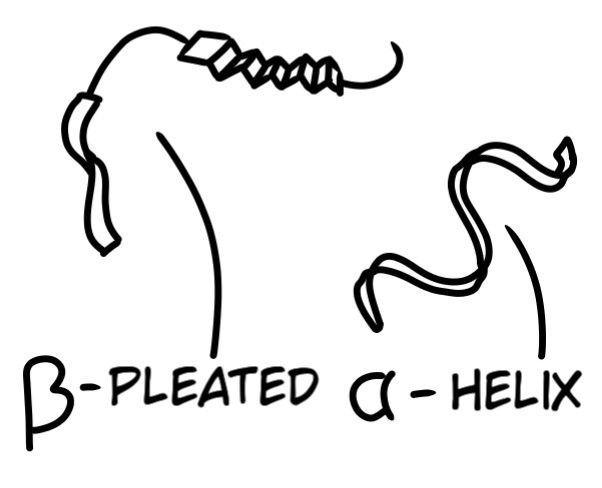
The drawing above (Fig. 9) is known as Tertiary Structure: Three-dimensional description of a protein's structure that is drawn in a ribbon-like fashion. Proteins maintain their three-dimensional structure via a variety of chemical and natural bonds that form between specific parts of the chain. These bonds include disulfide bonds: the bond between the sulfur atoms of two cysteine amino acids; Van Der Waals attractions: when the distribution of electrons, constantly changing, shifts to an unstable ratio which disrupts a molecule's electrostatic charge resulting in weak electrostatic bonds; Hydrogen bonds: when a hydrogen atom bonds to an negatively charged atom like oxygen; and Electrostatic attractions: the attraction of oppositely charges particles (positive attracts negative). But these bonds and attractions themselves do not account for the initial folding of a protein because, in biological systems, special enzymes aid in the folding, where these specified attractions can occur to maintain the structure.
In a paper published in the journal Nature on July 10, 2019, titled "Peptide Synthesis at the Origins of Life: Energy-rich Aminonitriles By-pass Deactivated Amino Acids Completely", Synthetic Chemist Matthew Powner says:
"...Peptide biosynthesis is now orchestrated by complex host of genetically encoded enzymes, but it is inconceivable that these sophisticated and coordinated macromolecules suddenly emerged at the origin of life", and "...Peptides are widely assumed to be products of amino acid polymerization reactions. Whilst conceptually simple, in practice, there are good reasons why these reactions are ineffective in water."
(https://communities.springernature.com/posts/peptide-synthesis-at-the-origins-of-life-energy-rich-aminonitriles-by-pass-deactivated-amino-acids-completely Italics are mine)
Zwitterionic: A molecule that contains parts with both positive and negative charges that result in an overall neutral net charge. (The molecule has a total charge of 0)
Chemical Species: A specific form of a chemical substance.
Nucleophile: Electron-rich chemical species that donate electrons for bonding.
Electrophiles: Electron-deficient chemical species that must receive electrons for bonding.
A big issue is that the zwitterionic nature of amino acids prohibits them from acting as good nucleophiles. In simpler terms, these amino acids must have an electron-rich nature to perform the correct chemical reaction that forms a peptide bond. The peptide bond is a nucleophilic acyl substitution reaction where the amino group of an amino acid donates electrons to the carboxylic acid (COOH) of another amino acid to form a peptide bond, also called an amide bond. This reaction generates a water molecule (which creates the water issue mentioned earlier). Besides this, biological peptide synthesis and chemical peptide synthesis are performed in completely different directions (https://www.youtube.com/watch?v=0Hv6KjB0j8Y&list=PLILWudw_84t2THBvJZFyuLA0qvxwrIBDr&index=8 10:30-12:45).
Chances of Peptide Formation Via Random Forces
Let's begin with a simple glycerine amino acid. It has 0 isomers, being the only amino acid with no stereocenter. It has some good chances of forming, and when two glycerine molecules bond together at the correct site, they can form a dipeptide (two amino acids) called Glycylglycerine. The chances of this dipeptide forming are very high, being that glycerine has three possible connection points (the NH2, O, and OH), it has a 1 in 3 probability of forming the right bond. To have two of these bonds, we have 6 total possible connection sites, making the chances of this dipeptide forming 1 in 9. This is a pretty high chance. Keep in mind that this is only two amino acids, and the simplest amino acid.
Let's take three amino acid types, and calculate their chances of forming, and then extrapolate that to see the chances of forming a longer peptide. I am choosing Tryptophan, Methionine, and Lysine. Tryptophan (Fig. 10) can exist in 2 isomers and has 3 connection sites (The COOH, NH2, and NH). This makes our equation (2 x 3).
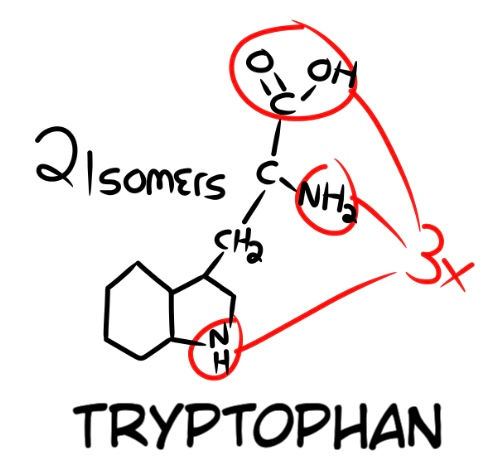
The next amino acid is Methionine (Fig. 11), and it has 4 possible connection points (the COOH, NH2, S, and CH3). It can also exist in 2 possible isomers. Now, say we have our methionine bond to our tryptophan, it has three possible areas to bond to. After our tryptophan has been bonded to the correct area, the newly bonded methionine has 3 remaining connection points, making our equation (2 x 3 x 2 x 4 x 3).
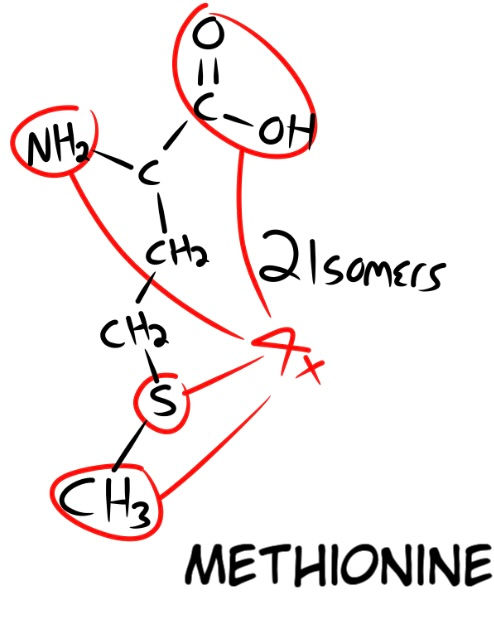
The last amino acid we want is Lysine (Fig. 12). It has 2 isomers and 3 functional points. After our lysine has bonded to one of the three possible remaining sites on the methionine, it also has 2 remaining connection points. This makes our final equation for all three (2 x 3 x 2 x 4 x 3 x 2 x 3 x 2), which equals out to a probability of 1 in 1,728. I will use this as our basis for calculating a further chain of amino acids by random chance. Say we wanted 6 amino acids in total. We can take our probability of 1,728 and multiply it by itself to calculate the chances of three more amino acids being added, randomly bonding to the correct functional connection sites. This makes our probability of 6 amino acids 1 in 2 x 10^6. Scientific notation, for those who are unaware, is written with exponents applied to the number 10 ( This writing program does not have superscript, so when i type ^ and then a number, that refers to the exponent. For example, 1 x 10^6 is the number 1 followed by 6 zeros, or 1,000,000.)
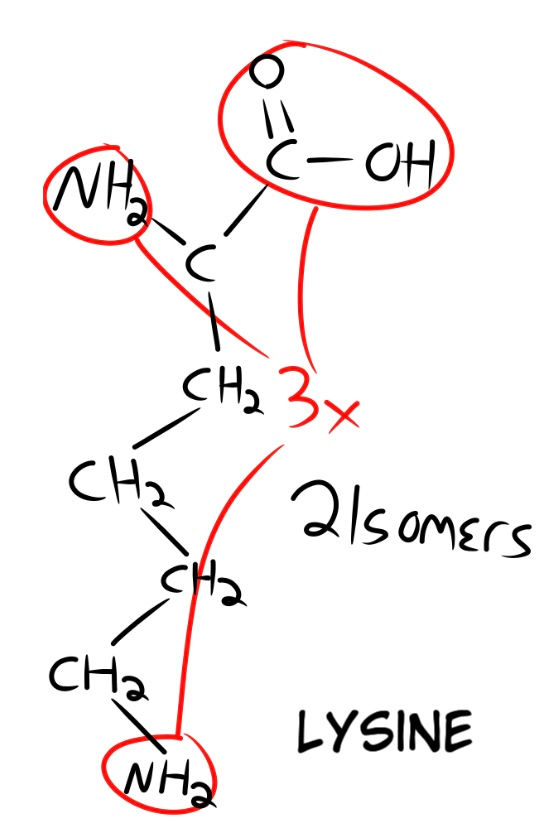
Once you get to 18 amino acids, your probability runs as high as 2 x 10^19, a number far surpassing the number of seconds in 14.8 billion years. For even more clarity, once you get to 84 amino acids, the chances surpass 1 in 1 x 10^73, a number surpassing the amount of observable particles in the observable universe at 10^70 (10 followed by 70 zeros!).
Nucleic Acids (DNA and RNA)
Nucleic Acids: Polymers of Nucleotides
Nucleotide: A phosphate bonded to a ribose or deoxyribose sugar bonded to a nitrogen base.
Nucleic Acids are made of nucleotides; a phosphate group bound to a desired carbohydrate sugar (Deoxyribose or Ribose) that is then bound to one of four nitrogen bases: Adenine, Cytosine, Thymine/Uracil, and Guanine. A detailed explanation of the structure of DNA and RNA can be found in the first article of this series. I will provide some more information here. There are two types of nucleic acids present in life, DNA and RNA. The nucleotides, which are the monomeric units of DNA, also have different structures for each type, although they are similar. A Ribonucleoside is the compound used in RNA nucleotides. Recall from the previous article where I mentioned that when a base and sugar are bonded, it is called a nucleoside, and once a phosphate group is bonded, it is called a nucleotide. Ribonucleotides use a sugar called D-ribose, whereas Deoxyribonucleotides use a different sugar called Deoxyribose, which lacks one hydroxyl group (-OH). Before you even have a nucleotide forming, Abiogenesis researchers must first have a way to form the correct sugars. One of the favored reactions is called the formose reaction that generates billions of different compounds and their isomers, with small trace amounts of the incorrect ribose forms. Even then, the mixture reacts to create asphalts, and Lee Cronin just buys the desired trace ribose in 100% purity from a manufacturer. The nitrogen bases that are used are classified into two main groups. They can either be derived from Pyrimidine (C, U, and T) or Purine (G and A). When a nucleic acid is formed in a helix, the phosphates and sugars are rich in hydroxyl groups that align along the outside of the backbone and interact with water and other compounds, leading to unwanted branching during synthesis (if these are left unprotected).
In a prebiotic scenario, a mix of phosphates, sugars, and nitrogen bases must combine to form the desired nucleotides that then must form either a single helix chain (RNA) or two chains in a double helix spiral formation that are connected via the inner lining of nitrogen bases that bind to eachother along the sugar backbone (DNA) using a different sugar. Therefore, a chemical reaction must be proposed that can properly combine the raw materials (Phosphates, sugars, and bases) into the desired nucleotides. Another reaction must then connect these nucleotides into the long spiral helices that form the DNA and RNA molecules. Moreover, these reactions must form nucleic acids encoded with meaningful and useful information that code for the construction of proteins that perform biological functions within the cell (a complex sequence of As, Cs, Ts, and Gs). Without any prebiotic forces present that perform the requirements mentioned, we are left to the blind chance of the molecular interactions.
Chances of Adenine RNA Nucleotide Formation Via Random Forces
For calculating what the chances of random formation would be, I am using an adenine ribonucleotide (RNA nucleotide). Before we begin, we must realize the assumptions that are given considering these chances. We are assuming that there is a mechanism that produces a decent amount of the right forms of ribose. We are also assuming that there are no forms of anything but our D-ribose. Are you ready?
To begin, let us look at D-ribose, the sugar used in the RNA nucleotides. D-ribose has 5 main forms, and the form that life uses is the cyclic form of beta D-ribose named B-D-ribofuranose. We are not taking into account the 8 isomers that each form has, only the fact that there are 5 forms we could have bonding. Now, looking at our beta D-ribose, it has 4 hydroxyl groups (-OH or -HO) that will compete for coupling. This makes our equation (5 x 4) from the 5 forms and 4 hydroxyl groups.

Now we have our phosphate bonding to the correct hydroxyl group of the ribose. This is why we have our 5 forms multiplied by the 4 possible connections for our phosphate. This means that our remaining locations for a nitrogen base are 3. But the base we chose, adenine, has three functional groups that could bond to our ribose.
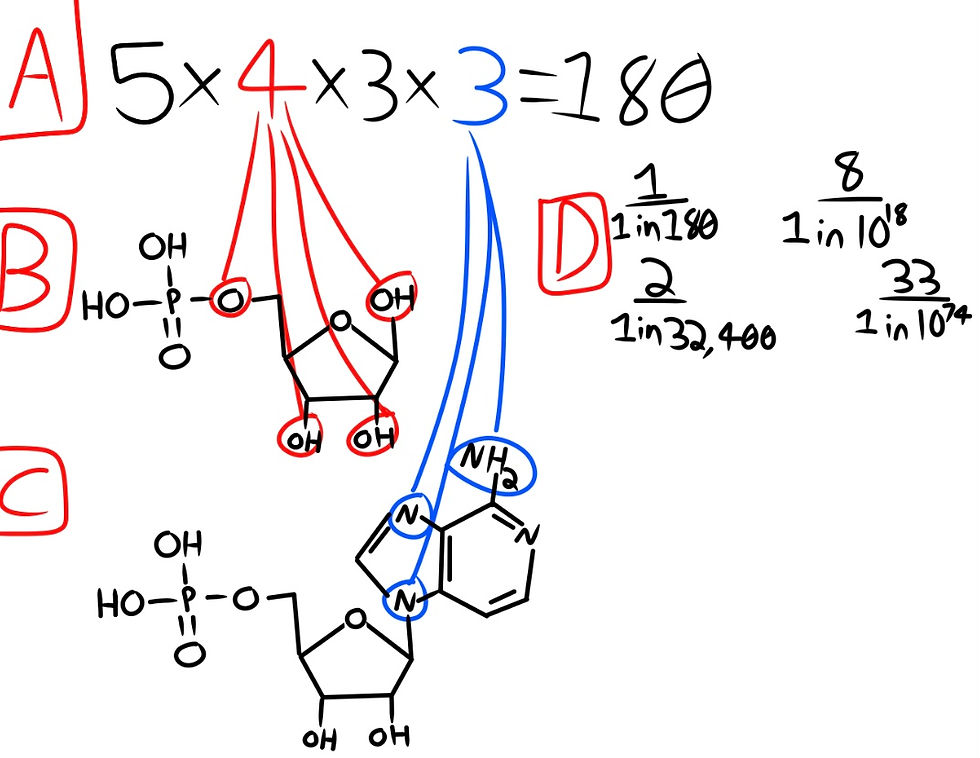
This would make our equation (5 x 4 x 3 x 3), having our 5 forms of ribose multiplied by the possible connection sites for our phosphate, multiplied by the remaining sites, multiplied by the possible connections of our adenine base. This comes out to a chance of 1 in 180 possible adenine nucleotide arrangements, where only 1 is useful for life.
Now, let's assume that there is a prebiotic mechanism that couples these nucleotides in the correct way (at the right angles and the right groups). All we need now is to know the chances of consecutively forming these correct forms. And to save us some hassle, let's use our adenine calculations as a basis for the chances of having multiple nucleotides bonding. Let's also assume that the nucleotides can be sequenced in a meaningful and functional way, containing information for coding proteins and such. Despite all of these assumptions straying far from what can be done in a lab, we shall see that even given these assumptions, the chances are far from human comprehension.
To get 2 of these to form in sequence, the chances are 1 in 32,400 (180 x 180). To get five, it is 1 in 1 x 10^9. Moving upwards of 8 in a row gets you 1 in 1 x 10^18, which surpasses seconds in 14.7 billion years. When you get to 33, the chances surpass particles in the observable universe. So with all the diversity of possible spatial configurations of each single nucleotide, we can see how in a prebiotic scenario, chance alone cannot account for the sheer length even the simplest RNA molecules would need to be.
Polysaccharides (Carbohydrates/Sugars)
Polysaccharide: A Chain of carbon sugars, a carbohydrate polymer.
Monosaccharide: Single sugar molecule of a polysaccharide.
Carbohydrates are carbon-based sugars called Saccharides. Saccharides are the monomers of Polysaccharides; the polymer of saccharides. Are saccharides able to be synthesized in life-friendly forms? Dr. James Tour notes that there are zero prebiotic methods for making saccharides, only hard-to-perform modern laboratory methods. Unlike the layman's interpretation, monosaccharides naturally form in various ways, not only the life-friendly form (recall the isomeric diversity mentioned earlier).
There are a total of 20 different types of naturally occurring monosaccharides, with many different isomers, and a certain type of sugar is used in life. In RNA and DNA nucleotides, Pentose Sugars are used as the central structure, and pentose sugars can have three or four stereocenters depending on whether they are open or closed. Closed pentose sugars have four stereo-centers, so 16 isomers; while there are three stereo-centers in the open form, so 8 isomers. All of these types are chiral, so this complicates things further when a mixture is racemic because not just one form of a pentose sugar will form: all isomers + their chirality. In nucleotide structures, only the closed forms are used.
So, in a prebiotic scenario, an Abiogenesis researcher must present a natural reaction that produces the correct forms and concentration of the right types of monosaccharides. Then there must be a reaction shown that can polymerize these into the correctly linked polysaccharides.
Chances of Disaccharide and Polyaccharide Formation Via Random Forces
Nobody is able to create the right forms. And the chances of natural forces randomly producing them are not favorable as well. Take, for example, (+)-Lactose: A disaccharide (2 sugars linked together) found in milk. (+)-Lactose consists of two monosaccharides connected by a glycosidic linkage shown below. This linkage is formally called a Beta 1,4 linkage because the link is connected to the 4th carbon of one sugar, and the 1st carbon of the next, also shown below. (+)-Lactose is made up of one D-glucose linked to one D-galactose.
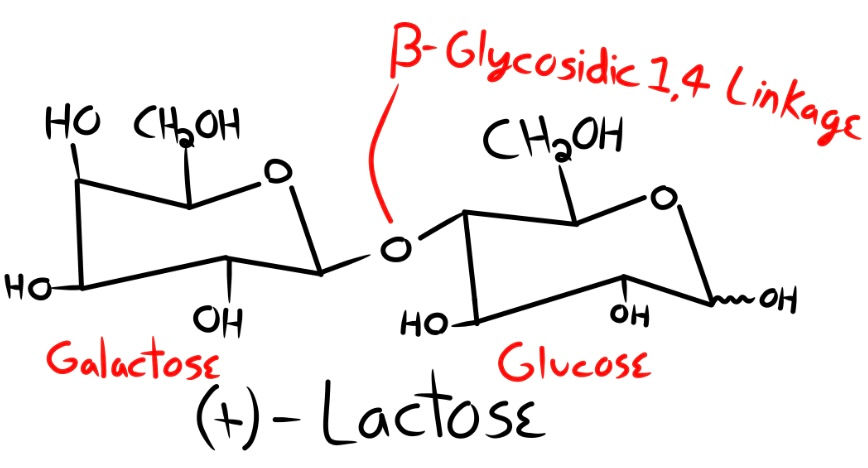
What are the chances that one of these would form, assuming natural processes can produce galactose and glucose with homochirality, but not assuming isomer purity?
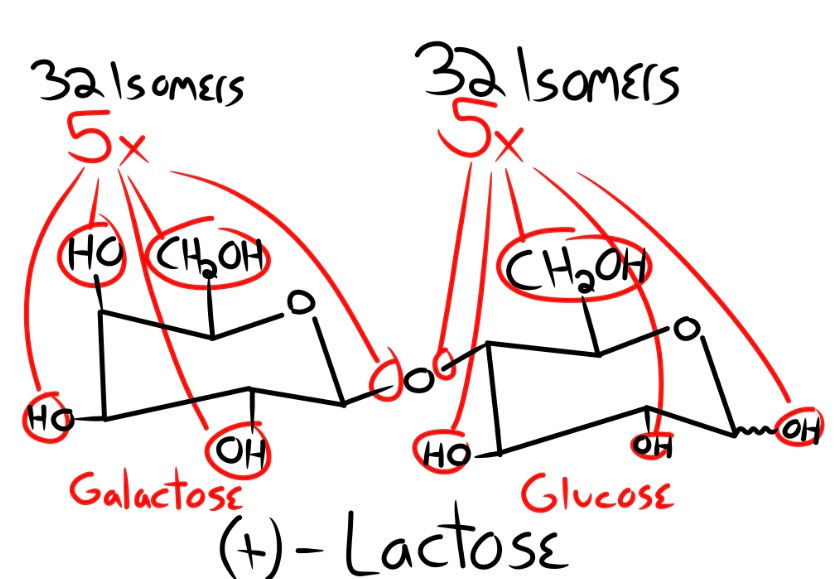
Here is the logic of my math. Galactose has four hydroxyl groups (OH) and one hydroxymethyl group (CH2OH); that is, 5 reaction sites that would compete for connection. Galactose has 32 possible isomers, thus making our equation (5 x 32). We now want to link our glucose molecule to our galactose. Glucose also has the same number of reaction sites, 5, and 32 isomers. This makes our equation (5 x 5 x 32 x 32). Two possible types of linkage can happen: a beta glycosidic linkage and an alpha glycosidic linkage, which means we must add a multiple of 2 to our equation (and this is leaving out the possible sites for linkage to happen). This makes our final equation (5 x 5 x 32 x 32 x 2). The chances of forming one single (+)-Lactose are 1 part in 51,200. Now that we have seen the very generous chances of forming one single disaccharide, let’s move on to a polysaccharide.
The Polysaccharide I have chosen to calculate is Cellulose: a polymer of glucose connected by beta 1,4 glycosidic links. Shown below is a drawing of cellulose’s structure.
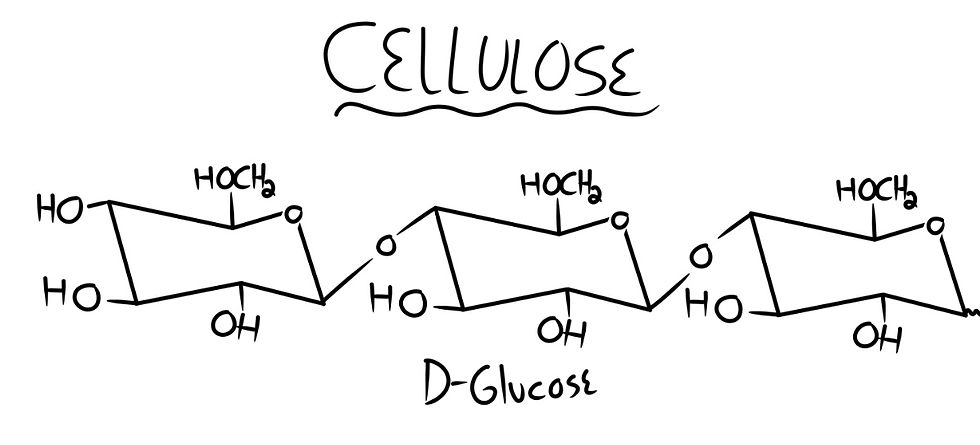
Fun Fact: The reason humans cannot digest cellulose is because of the strong 1,4 glycosidic linkage. Our bodies cannot break that link to release the glucose to be stored and used as energy. Horses, cows, and other animals possess enzymes and microbes that are able to break down cellulose into glucose molecules.
Now, let’s begin these calculations. D-glucose, as mentioned before, has 4 hydroxyl groups (OH) and 1 hydroxymethyl group (HOCH2), which makes 5 total reaction sites. It also has 32 possible isomers, which makes our equation (5 x 32). Now we want another D-glucose to connect to our first one, adding another 5 reaction sites and 32 isomers, making our equation (5 x 5 x 32 x 32). There are 2 possible linkages: beta glycosidic and alpha glycosidic, and 4 remaining reaction sites on our second glucose molecule. This means that to connect one glucose molecule to another, the equation is (5 x 5 x 32 x 32 x 2 x 4). The chances of forming and linking a glucose molecule to another are 1 in 102,400.
But we cannot stop here. Polysaccharides are made of many monosaccharides. The smallest cellulose is 3 glucose molecules long, and the chances of forming that via random chance are 1 part in 1 x 10^9 or 10,485,760,000. More general cellulose molecules are thousands of glucose molecules long, but what are those chances? Once you get to 14 sequenced glucose molecules, you are at a chance of 1 part in 1 x 10^70. But why did I stop there? This astronomically large number (10^70) is the number of elementary particle interactions in the observable universe. So this means that by random chance, you have about the same probability of finding a single specified atom out of all the others in the universe. Any number above 14 monosaccharides in a polysaccharide means you have better chances of finding that one atom than forming the polysaccharide via random chance.
Those calculations were very generous, because what are the chances of forming D-glucose via random chance? Well, here's a short rundown of that issue. Glucose can reside in 3 different ring forms: 6-member, 5-member, and open. The 6 and 5-member pentose rings have 32 possible isomers each, and the open form has 16 isomers. This is why synthesis and polymerization are difficult without modern techniques; there is so much variation that interacts with reactions within the mixture. Anyhow, our equation looks something like (3 x 32 x 16). The chances of forming a single glucose molecule via random chance are about 1 part in 1,536. This is before we can create our polysaccharide, and is exactly why abiogenesis researchers have no idea how to synthesize these molecules.
I hope this can put polysaccharide synthesis into perspective. If not, then I am convinced no amount of evidence can convince you otherwise.
Phospholipids (Lipid Bilayer)
I will include my rundown on lipid construction from the previous article in this series, along with this section.
Phosphate Group: A molecule consisting of a phosphorus atom bonded to four oxygen atoms.
Glycerol: Also known as Glycerin, is a carbon atom bonded to three hydroxyl groups (one oxygen atom bonded to a hydrogen atom)
Fatty Acids: A carbon atom bonded to a hydroxyl group (Oxygen and Hydrogen atoms bonded together, OH), double-bonded to an oxygen atom, finally bonded to a chain of carbon and hydrogen atoms that form the tail of the fatty acid.
Bacteria: Members of a large group of unicellular organisms that lack organelles (pretty much cell organs) and an organized nucleus (where genetic code is stored).
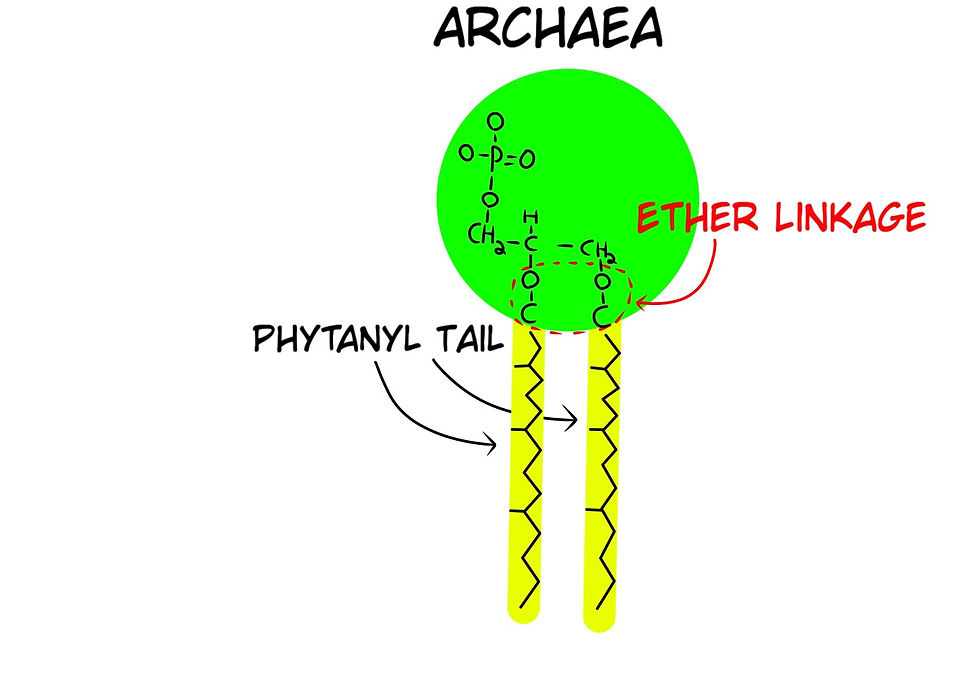
Archaea: Unicellular (single-cell) organisms that also lack organelles and a nucleus, but have a different membrane construction than bacteria.
Phospholipids are the main component of cell membranes, and they are made of three smaller molecules: a phosphate group, a glycerol molecule, and fatty acids. The phosphate group is attracted to the presence of water, whereas the fatty acids repel water. Phospholipids can sometimes self-assemble into a lipid bilayer, where two layers of lipids gather with the fatty acids in the center of the arrangement and the phosphates facing the water.
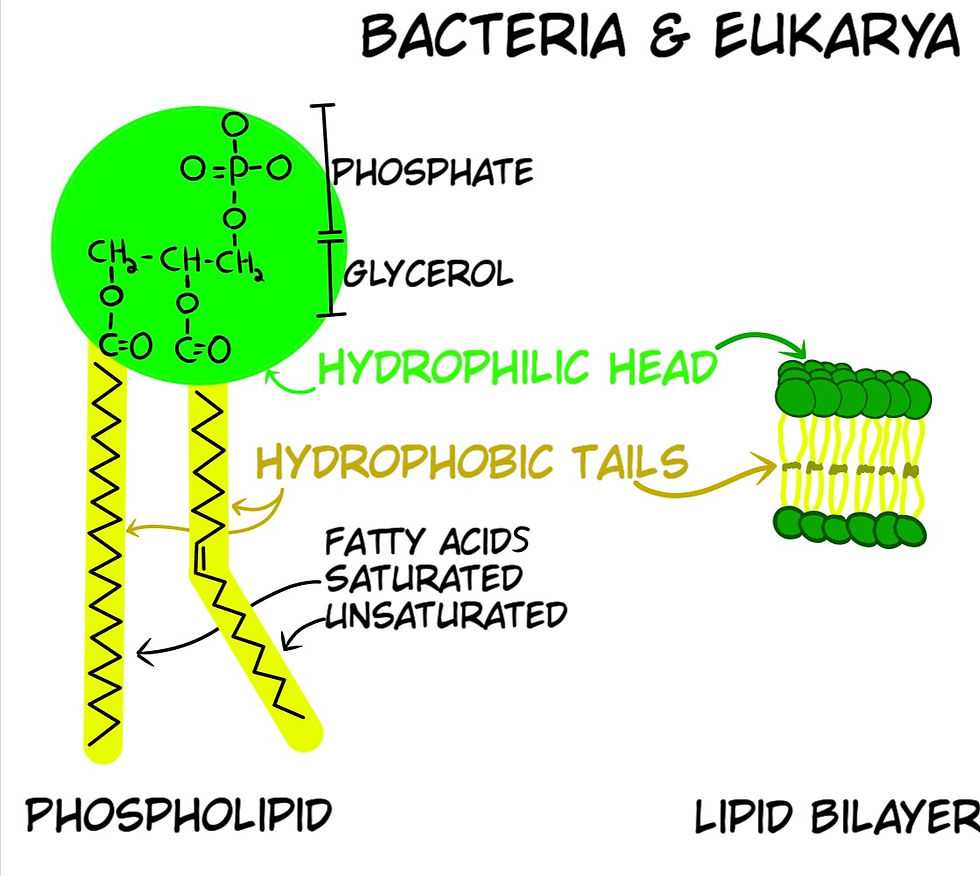
For Abiogenesis, lipid bilayers raise a major issue as to how they could have formed because bacteria and archaea have different phospholipid configurations. Archaea use an Ether linkage for their tails, whereas Bacteria & Eukarya use an Ester linkage; two different molecular structures (Figs 18 & 19). As well as the enzymes that manufacture the glycerol in both are different, which means the coding instructions in their genetic code are different. Despite this known fact, the dogma is that these two have a common ancestor, without an explanation as to how or when the genetic code was completely changed.
Fun fact, most recent and "secessful" Abiogenesis experiments to make phospholipids require dehydration of a mixture, where 0.2% of the phosphorus in the mix reacted to form phospholipids. The experiments created no phospholipids known to be used in any form of life, i.e. they are not life-friendly (Hargreaves. W.R.S. .Mulvihil, and D.W. Deamer, Synthesis of phospholipids and membranes in prebiotic conditions. Nature, 1977. 266(5597): 78-80.).
But the structure of lipids is not the entire issue, for cell membranes are not only constructed of phospholipids. Yes, phospholipids can sometimes self-assemble into a bilayer in the presence of water. A lipid bilayer consists of two layers of lipids, where the inside of the layers contains the lipid (hydrophobic) tails, and the outside contains the phosphate head (attracted to water). Sometimes, the bilayers can shift from a higher energy state to a lower energy state, where the layers form a sphere called a vesicle. Abiogenesis researchers must then create a lipid vesicle membrane. But wait, there's more!
A simple lipid membrane would kill a cell, because it needs a way to extract waste products and intake outside nutrients and compounds. Macromolecules simply cannot penetrate the membrane to the point of entry, and even the simple molecules like oxygen and carbon dioxide, which can enter freely, do so at a less-than-ideal speed. Which means that the membrane alone cannot account for a life-sustaining internal environment. Another issue is that bilayers are sensitive to temperature and can rapidly transition into a stacked formation instead of a sphere. In a living cell, there are lipid bilayer repair mechanisms that modify the composition of the phospholipids to remain in a vesicle structure. This process is sometimes called homeoviscous adaptation. Phospholipids also very rarely transition to the lower energy state of vesicle formation (Lasic, D. D., The Mechanism of Vesicle Formation. Journal of Biochemistry, 1988. 256(1): 1-11.)
A cell membrane must also keep a constant proton gradient, that being a higher concentration of protons on one side of the membrane than the other. If the proton gradient ceased in your cells, your life would end, and Rob Standler says, "Cyanide Poisoning works by this method" (Stairway to Life, Pg 142). This means that the membrane must be tight enough to block the passage of protons, while also allowing larger building materials, energy, and communication to enter, and allowing waste products to exit. This transportation must also be controlled because crucial materials cannot be expelled with waste products; likewise, waste products and toxins cannot be allowed to enter the cell. Modern cells do this via a set of specified pores that are embedded into the membrane; these pores are composed of proteins, which are created by the code inside the DNA molecule. The simplest membranes consist of 140 different proteins nudged into their membranes.
These pores cannot be left open. In cells, pores are specified, and some only open when triggered. A pore called Aquaporins is activated to allow the passage of water through the membrane. But water molecules entering the cell in a stream would act as a proton conductor and disrupt the proton gradient. Aquaporins rotate an entering water molecule perpendicular to the angle that would allow it to act as a conductor (Murata, K. et al., Structural Determinants of Water Permeation Through Aquaporin-1. Nature, 200. 407(6804): 599-605.) In ABC transporters, consisting of multiple protein complexes, used by E. coli, the binding of two ATP molecules to subunits located inside the membrane triggers the transporter to open and release a Mccj25 molecule through a passageway made by larger subunits inside and extruding the membrane. The energy of the ATP molecules is then used to close the outside subunits, preventing any contamination from entering the pore. Different life forms use different pores, all with their complex structures and functions.
Now you may be wondering. If these transporters are inserted into the membrane, and the membrane is impermeable to larger molecules, then how is a macromolecule like a transporter to be inserted into the membrane? The process in already living systems is extremely complex; here's a rundown. The DNA code that codes for the ABC transport is transcribed by an enzyme into mRNA. Then a ribosome snaps to the mRNA and, with the aid of tRNA molecules, delivers the corresponding amino acids from the code in the mRNA to the ribosome for polymerization. The ribosome then constructs a portion of the ABC transporter. It constructs a hydrophobic polypeptide called a signal sequence. A recognition molecule composed of proteins and RNA then recognizes the signal sequence and attaches to the polypeptide, prohibiting the ribosome from continuing. Another enzyme then delivers the ribosome, polypeptide, and recognition molecule to the desired pore for insertion into the hydrophobic portion of the lipid bilayer. The ribosome then continues to produce the rest of the transporter's proteins, constructing an ABC transporter successfully. This process is highly specified, only having a specific portion being constructed, halted, to then being inserted into an area where only that portion can reside. From there, the protein is embedded into the membrane, and the rest of the subunits can be constructed.
Inserting an ABC transporter into the membrane requires an already existing protein pore called the SecYEG translocon. The SecYEG translocon is inserted by another SecYEG, which begs the question of how the first translocon pore was embedded into the first cell membrane. Well, the cell membrane and its pores are inherited from the parent cell's membrane during replication, and no cell has ever been observed creating a pore-filled membrane from scratch. Supporters of Abiogenesis can only attempt to explain how the first complex membrane formed by divorcing from sound science, creating an extensive narrative that draws far too much speculation and imagination. Protomembranes cannot meet the requirements for basic life or begin to gain complexity to account for the inherited pores. There is no scientific evidence that life-friendly phospholipid bilayer membranes have been created in prebiotically relevant scenarios.
Chances of Phospholipid Formation Via Random Forces
This calculation involves a lot of assumptions. This is because the synthesis of phospholipids is no easy feat. I'll give a rundown that is covered in Dr. James Tour's video, going over lipid synthesis (the video can be found here: https://www.youtube.com/watch?v=QTQd5Ifqv2g&list=PLILWudw_84t2THBvJZFyuLA0qvxwrIBDr&index=11). As mentioned above, the main component of a phospholipid is a glycerol molecule. Which itself is achiral, meaning it has no mirror images that are non-superimposable on each other. In the pictures above, the glycerol molecule has two sides, and each one has active hydroxyl groups. Once these groups are bonded to something, say the two fatty acid tails, the achiral glycerol becomes a chiral molecule with isomers. The glycrol molecule has 3 groups that can bond, meaning we have four possible points for connection of our fatty acids and phosphate (phosphoric acid). When, say, a phosphoric acid comes, its OH group bonds to the glycerol to form a phosphate ester. The remaining OH groups on the glycerol can bond to our fatty acids.
So let's begin with glycerol. It has the three hydroxyl groups that, assuming there is a prebiotic reaction that does it correctly, can bond to our phosphate. After our phosphate bonds, there are 2 remaining groups for a fatty acid to bond to. This makes our equation (3 x 2), because after our first fatty acid is bonded to the glycerol, there is only 1 place left for the other fatty acid tail. This makes our chances rather generous, at a 1 in 6 chance of forming. But since these molecules have a stereogenic center in the glycerol, there are 2 possible isomers to take into account here, so the chances are actually 1 in 12 when we take chirality into account.
Final Remarks on Chances
Before we end this section, let me remind you that the chance calculations contained multiple assumptions that haven't been explained by the Abiogenesis community. We assumed that there are prebiotically relevant reactions that can produce some of the monomers of these molecules in 100% Homochirality. Moreover, with the phospholipids, we did not consider the chances of more than one forming in sequence. I chose not to do this because, as mentioned in the same subsection, the cell membrane is not just composed of lipids, but rather a large collection and arrangement of proteins that are specified to intake material or discrete waste products. For me, at least, calculating those chances is beyond my abilities. I only performed simple probability mathematics to show you that even in simple terms, the chances are far divorced from comprehension. I mean, I can't even begin to picture what 10^80 grains of sand would look like (because it would be far larger than the universe! Yet some of these chances surpass those numbers for even the simplest requirements of life. And these are assuming they form in isolation from the other classes of molecules, because if they were all mixed, they would all react to equilibrium, and you would have a useless mixture chemists call "asphalt".
Separation of Desired Products
After examining the various forms each molecule has, and taking into account the chances of them, and the fact that prebiotic reactions are not able to produce anything in 100% enantiomeric excess, we can see that there must be a way to separate the desired molecules from these vast mixtures. But before we tackle that, some critics claim that deep time is the saving grace to the extreme implausibility displayed above. The issue here, despite the chances exceeding available time to claim, is that time is the enemy to these biomolecules. You see, everything is degrading, decaying, heading down towards disorder. Consider the following: Some ancients stumble upon a flat area of land and decide to build a foundation for a temple, but famine strikes and they cannot finish their temple, leaving only the foundation. 2,000 years later, some settlers are passing through the area and find trees and weeds overgrowing the eroding foundation, so they decide to build the basic walls of a cabin and use them for storage, but later hardships drive them out of the area. 2,000 more years pass, and some kids exploring the woods of their neighborhood stumble upon the structure. Would it resemble the original foundation and cabin at all? Could a roof be built to complete the cabin? Can a structure be built with such time intervals between the steps? No, the wood would have rotted and fallen apart, and the foundation would have gone through many seasons of erosion and also be crumbling.
Similarly, each step of developing life is posed as having millions of years gapping between them, offering nothing but time to degrade into a mess of useless molecules, just to have another meaningless event happen to magically produce molecules, to have more time pass for that mix to degrade. Of course, energy input can overcome the second law of thermodynamics taking place, but the energy sources that supposedly provide the energy for these reactions are very well capable of destroying already created ones. Without some way to harness and manipulate the energy and protect against unwanted destruction, abiogenesis researchers have yet another stumbling block that they claim is not there.
Now that the claim of millions of years cleaning up the mess of math of the sheer improbability of these molecules forming has been refuted, these large mixes of isomers and chirality require a method of separating the desired molecules to one site so that they can hook together in the correct life-friendly way. I’ve heard folks respond to this with something like “the first biomolecules weren’t as complex as the ones today, and thus the calculations don’t work”, but this reveals a large misunderstanding of the issue. There is 0 empirical evidence that supports the notion that molecules and the chemistry that governs them were simpler or different in the past. Positing that as an answer to these issues has no evidential substance, and is completely based on a philosophical commitment to opposition.
Perfect Concentration of Polymers
Not only must these molecules and polymers be isolated from their resulting mixtures, but they must also be present in 100% enantiomeric excess. In other words, every single molecule must be the same chirality and correct form and isomer. Life uses the same set of lipids, 20 amino acids, 5 nitrogen bases, and one type of sugar. Yet there are thousands of other possible configurations that will be produced alongside these life-friendly molecules. Remember that all prebiotic reactions proposed by researchers produce mass mixtures of the various arrangements and forms of molecules. These are identified as “interactable mixtures” and “asphalts” (Robertson, M. P. and G. F. Joyce, The origins of the RNA world. Cold Spring Harbor Perspectives in Biology, 2012. 4(5).); (Benner, S. A., Paradoxes in the origin of life. Orig Life Evol Biosph, 2014. 44(40, pg 339-343.). That would be completely irrelevant to life because each different variation would react with each other, prohibiting prebiotic synthesis from even occurring, which is exactly why research requires a chemist to control reactions and protect molecules from branching during polymerization. Being aware that prebiotic chemistry produces all but the desired molecules and compounds, and expecting relevant interactions to occur with the very sparsely present desired molecules is delusion. I want you, the reader, to be fully aware of the irrationality of remaining committed to this religious belief in Abiogenesis and chemical evolution. And I want you to reflect on that and question whether you want to live knowing what you believe is contradictory to reality.
Formed by Chance?
Now that we have gotten a pretty decent overview of Abiogenesis and the requirements of life, let us turn to some objections that skeptics often bring up in an attempt to refute the intelligent design of the first life. The first claim I often hear is that pure chance could have been responsible for the formation of the first life. Well, with the calculations we have performed, given massive unexplained assumptions, it still did not result in favorable chances of their formation via the natural forces that govern their behaviour and interaction. Moreover, researchers recognize the improbability of life's minimal complexity arising by chance. And despite many claiming that natural selection is responsible, misunderstanding what theory we are dealing with, that will not work either. Natural selection changes organisms when they are already alive, and Abiogenesis is before any life, being just non-living molecules.
The simplest enzymes contain about 60 amino acids, and considering that every 3 nucleotides codes for a single amino acid, that means it requires a total of 180 nucleotides of DNA information to code for them. For the simplest enzymes to be produced, and using our 1 in 180 chances for an Adenine ribonucleotide, that would be a random chance of 1 in 3 x 10^225. Or 3,000,000 followed by 219 more zeros. And when we consider the inter-relationship between specified proteins and other important macromolecules, their odds of forming have been calculated to 10^40,000 to 1 (Davies, The Fifth Miracle, Pg 138).
I think we have come to a sobering point to draw a conclusion that the active role of random chance is not in any comprehensible way responsible for the formation of the first life.
Formed by Necessity?
This claim comes from looking around us. When confronted with the question of life forming by necessity, they look around at all the life present and conclude, "Life must have formed by necessity because it is here now". This line of thinking is faulty because it assumes that, because there is life present, life must have formed by necessity and not by an intelligent agent. This is answering the question about an assumption (life forming by necessity), with the very assumption (that an intelligent agent cannot be responsible for life because it formed by necessity). Well, for life to form by necessity, these biomolecules must also form by necessity, and couple into the correct linked polymers by necessity. I am so sorry to inform you that the refutation to this claim is extremely simple.
The fact that all biomolecules have non-usable mirror images and multiple spatial configurations rules out the possibility that necessity played a role in forming these. The fact that no chemical reactions have been produced naturally that can produce ONLY the desired molecular forms completely demolishes the necessity argument. If they were formed by necessity, then there would be no diversity in their formation, with only a single one usable to life. This means that the life-friendly molecules and systems did not form by necessity, because events unnecessary to starting life do occur in favor of life-bearing ones.
Where Could it Have Happened?
It is not really known in the Abiogenesis community; there is little agreement on where life began, and what the conditions of the early Earth were to produce it. Let's take a short look at the issues with proposed locations for the beginning of life.
Could it Start in the Atmosphere?
Many have proposed that life may have started in the atmosphere, or at least early proponents of Abiogenesis thought so. In 1953, the Miller-Urey experiment was conducted. Stanley Miller and Harold Urey mixed ammonia, methane, hydrogen, and water vapor, then passed an electric charge through the mixed gases. The research paper was titled "A Production of Amino Acids under Possible Primitive Earth Conditions". In which they produced some amino acids (Glycine, alpha Alanine, and beta Alanine). The mix of gases is known as a reduced atmosphere, meaning it contains no oxygen. Mixing oxygen and methane with a spark would not have gone well for Miller and Urey, and the electrical discharges they used to produce the larger amino acid molecules were strong enough to also destroy them. So they made a setup that protected the amino acids produced from the discharges themselves, a scenario very hard to imagine happening on an early Earth.
But the experiment partially completed creating life-friendly amino acids. In 2013, one of Miller’s former students reanalyzed the products of the experiment. When Jeffrey Bada added hydrogen sulfide to the reducing atmosphere, he found ten of twenty types of amino acids mixed with other amino acids, amines, and other irrelevant molecules that would interact with the desirable amino acids in a prebiotic scenario. In the years following Miller's initial experiment, the atmosphere of the prebiotic Earth was under debate. In 2011, Dustin Trail at the Rensselaer Polytechnic Institute studied the oxidation found in cerium that was inside zircons believed to be as old as the Earth. They concluded that the oxidation was higher than expected, which meant that a prebiotic Earth would not have likely had a reduced atmosphere, and would have had an entirely different set of gases (Carbon Dioxide, Water vapor, nitrogen gas, and Sulfur Dioxide).
This experiment and its issues mean that life could not have originated in the atmosphere of the early Earth.
Could it Start in Water?
The first person to propose the location of water as a possible place for the origin of life was a Soviet Biologist, Aleksandr Oparin, in 1924. He claimed that life may have started in the oceans, resulting in amino acids that bonded to form primitive proteins. But from what we now know about the process of making a protein, it is very interdependent on the informational relationship of DNA, RNA, existing proteins, and Ribosomes. Water also prohibits the polymerization of amino acids and actively degrades most biomolecules without an already existing biological system to sustain them. Water is essential to life, but detrimental to getting to started. Also, a consistent source of phosphate for the formation of DNA, RNA, and ATP is not prevalent in an aquatic environment. Also, there would be no means of controlling the chirality and isomeric diversity of each molecule produced.
But some have claimed that hydrothermal vents are the place for life to form. But this, too, has issues. The extreme temperatures and acidity of black and white thermal vents on the ocean floor are prposed as a possible location for life's origin, but recently, Nick Lane of the University of London argues that a completely different type of hydrothermal vent is required, that a non-smoking alkaline vent is the right one (Nick Lane, The Vital Question, 2016.). Thus, the possibility of life emerging in water is highly unfavorable.
What About the Information of DNA?
Now that we have looked at solely the molecules of life themselves, we are still missing a very crucial component to get life started and maintained. This component is the existence of information in the sequence of nitrogen bases of DNA. Proteins, Ribozymes, ribosomes, enzymes, and other molecular machinery and building blocks are guided by the specific nucleotide sequence of DNA. The sequence is informational, and every three nucleotides of mRNA form a "codon" that codes for a specific amino acid that corresponds to the original sequence of the DNA.
There are levels of information too. For example, I put a monkey on a chair and have him type a random sequence of letters.
"sjiwebcerbcr3ic03rcercebc deceocnero ecoricnrecrn3c"
That random sequence has statistical value, that being a specifically random sequence that is unlikely to happen again, but fails to be recognized as informative itself. Using an analogy used by J. Warner Wallace in his book "God's Crime Scene" (Pages 86-88). Say A monkey typed out:
"grand the, eats letting"
The sequence of letters strikes us as impressive and contains some recognizable words, but still fails to communicate anything informationally valuable. Now, imagine the monkey types again and yields:
'grandpa is eating"
Now the monkey is showing an even higher level of intelligence. This sentence displays meaning. The monkey has an idea about grandpa performing an action: eating. The monkey is conveying meaningful information. Now, what if the monkey types this:
"Let's eat, Grandpa!"
Now the sentence has meaning, intent, with direction for a specific action. The monkey wants to be fed by Grandpa. As Jim Wallace says, we have moved from Statistics (the information itself), to cosyntics (recognizing patterns and changes), to semantics (adding meaning and context to the patterns), to pragmatics (focus on the application and use of information) and apobetics (the highest level of information, where there is a purpose of the sender as they use symbols, words, phrases, and sentences to accomplish a specific outcome).
The last sentence was instructive and displayed the monkey's desires and motivations. The monkey was displaying the highest complexity of information. But that's not all, because a good way to test the informational value of something is to see the impact of modifying the information itself. If we change one character from the first sentence for another one (red, and underlined below), nothing meaningful changes in the information; only the statistical value of it happening again may change slightly:
"sjiwebcerbcr3ic03rcercebc Oeceocnero ecoricnrecrn3c"
But if we change something in the last sentence (like removing the comma, underline below), the message changes meaning, intent, and emotion:
"Let's eat Grandpa"
Now the monkey doesn't want to be fed by Granpa anymore, he wants to full-on devour him! If the change of the data causes massive detriment to the overall meaning and intent of the information, then you can be very confident that you have a very complex and high level of it.
In the same exact way, the specific sequence of nucleotides in DNA directs with a very high level of intent and meaning the construction of biological molecules, genes, and their regulation. The length of the human genome is 3 billion base pairs long, and changing just one single nucleotide can very often cause death or major dysfunction of a protein or molecule. Sickle cell anemia is caused by a single-nucleotide mutation, and changes of nucleotides during an organism's fetal development almost always result in premature death.
These nucleotide sequences are far more complex than statistical information; they are semantically, pragmatically, and apobetically informative sources. And the fact that a discrete set of characters is used to convey and communicate this information adds to the complexity. Moreover, small changes to an organism's genes can result in different physical traits, another example of the modification test being applied. We can change the meaning and goal direction of the DNA code by making small, sometimes single-character changes, which is a for sure evidence that DNA contains the highest level of information present in the universe. As Bill Gates has said, "DNA is like a computer program, but far, far more advanced than any software ever created."
How Do We Know There Was An Author of the Code?
Where does information come from? This is a very significant question when considering the origin of life. This is because we find high levels of information and information processing software at every single nook and cranny of the micro-biological world. To stay scientifically honest, I will use what the uniform human experience has provided us with: that information comes only from intelligent sources. If we stick with strict materialism, life and information must have arisen from matter, chance, and the laws of chemistry and physics. But as we have already seen, those explanations fall short of experimental evidence, and thus lack empirical support and are more a philosophical commitment to naturalistic materialism.
The locations of Earth that are claimed for the origin still require an explanation for the information; The massive timeframe for Abiogenesis to occur, ignoring the 2nd law of thermodynamics, still doesn't explain how the information arose; Even if life arose from chance and necessity, this does not explain how and where the information came from; and all the models of Abiogenesis still require and explanation for the emergence of highly specified irreducibly complex information.
"There are neither bonds nor bonding affinities-----differing in strength or otherwise-----that can explain the origin of the base sequencing that constitutes the information in the DNA molecule" (Stephen C.Meyer, Signature in the Cell, Pg 268).
"We are still left with the mystery of where biological information comes from.... If the normal laws of physics can't inject information, and if we are ruling out miracles, then how can life be predetermined and inevitable rather than a freak accident? We always come back to that basic paradox" (Davies, The Fifth Miracle, 258)
We are left with a sadening paradox: The laws of nature are not able to produce information, yet information is the crucial component of all life.
Moving on to how we can be confident that there was an author of the code, we can look at the characteristics of designed objects by using a helpful acronym Jim Wallace presents, "DESIGN". Every object that is intelligently designed displays these characteristics: Dubious Probability, Echoes of Familiarity, Sophistication and Intricacy, Informational Dependency, Natural Inexplicability, Efficiency/Irreducible Complexity, and Decision/Choice Reflection. Jim uses these to look at some systems found in living cells, such as the Flagella and the Type III Secretion System. I suggest you read Jim's section of "God's Crime Scene," where he goes over these characteristics in these molecular machines (God's Crime Scene, Pages 93-112). I will use this acronym and apply it to the code found in DNA to show you how we can know life was designed, even at its core, the information found in DNA.
Dubious Probability
When we look at the genome of living cells, we observe a relationship between the sequence of nucleotides and the molecules being produced from it. As we have seen, the chances of the DNA molecule itself forming are staggeringly dubious and low. With the simplest enzymes consisting of 60 amino acids, being formed from the 180 specified, information-bearing nucleotide sequence of the DNA. The chances of those randomly forming being 1 chance in 1 x 10^225, we can see that the DNA molecule bears a dubious probability of its formation via natural forces.
Echoes of Familiarity
Gene Regulatory Network: a collection of molecular regulators that interact to control gene expression levels and protein production, ultimately determining a cell's function
It is no question that the code in DNA highly resembles binary code used in computer software today, and as mentioned before, the genome is like a computer program, except far more advanced than anything humans can create. You can read more about the discrete nature of the DNA code here: https://www.ptequestionstoeden.com/post/does-dna-contain-digital-information. The fact that the DNA code also inhibits a system of interdependent regulatory networks of proteins that alter genes also tells us it resembles something humans deal with. Displayed below is a GNR, and I want you to look closely at what it resembles.
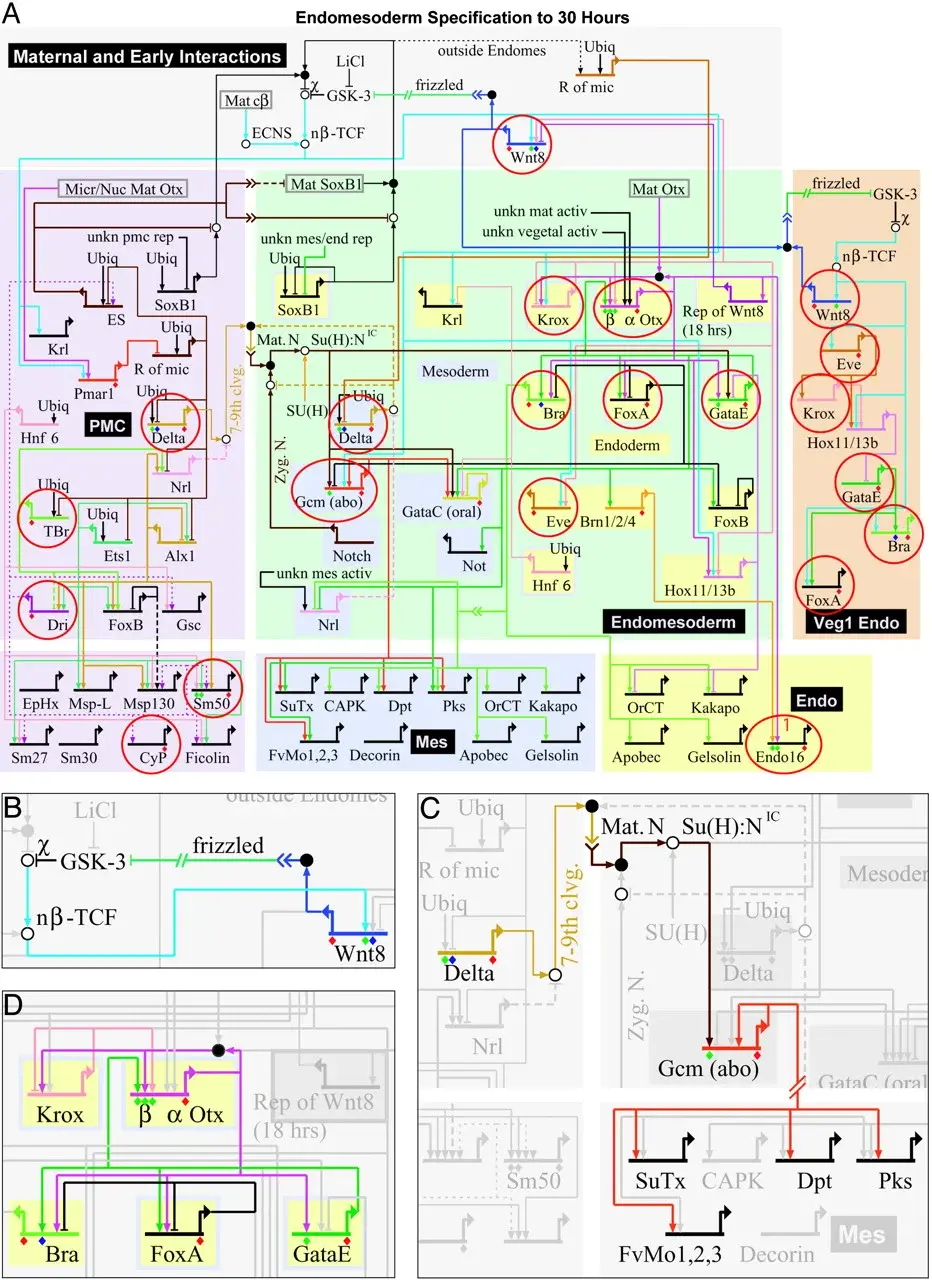
This is a mapping of a network that drives the specification of whether a sea urchin cell will become a mesodermal (digestive tract cell) or endodermal (muscle, bones, circulation, etc.) cell. This looks like an integrated circuit diagram used in engineering, and also resembles the mapping of a PLC or other logic control system. We can be highly confident that DNA echoes familiarity.
Sophistication and Intricacy
In the bacterial flagellum, a molecular motor that rotates a thread to propel the bacteria, there are over forty different, specifically shaped proteins that combine into many complex subunits to create a rotary motor. This would require a large host of information in the DNA to code with intent to create these proteins in a specific sequence to result in the folding of a specific structure. The fact that GRNs exist within the genome, all being extremely specific and goal-oriented, also tells us that DNA exhibits extreme sophistication in its design and the designs that it produces. The complexity of the micro world was also unexpected by the scientific community, because before the discovery of the complexity of the cell, people believed cells were simple blobs of cytoplasm.
Information Dependency
The code in DNA has been shown to be infromative, extremely informative. Usually, inside the genome, sequences that code for the construction of a single enzyme or machine are found next to each other, like words written on a set of directions to a Lego set. These sequences are called Operons. DNA, and all life, is information-dependent.
Goal Oriented
When you go and buy a hose clamp, it does not take you long to recognize that it was designed with a goal in mind. The thin metal sheet that is formed into a ring, with a small assembly that the ring gets inserted into, that, when turned, pulls more of the metal sheet through, tightening the ring. This object was obviously designed to tighten around something and be loosened for possible removal or reapplication. DNA shows us the same type of characteristic. The fact that a specifc sequence of nucleotides results in an entire system of transcription and translation that results in a specifc sequence of monomers to produce a specified polymer that may fold into a specific shape to perform a specific action that results in a specific event happening that can be beneficial.
The code in DNA is for sure goal-oriented and sends a message with intent.
Natural Inexplicability
As already shown and repeated, the natural laws of physics and chemistry are completely unable to explain the formation of life and its information. There is simply no chance or necessity in nature that accounts for the random formation of semantic and apobetical information; that level of information only comes from intelligently rational minds.
Efficiency/Irreducible Complexity
Earlier, when we tested our monkey's sentence by modifying the characters, we saw that the information can not be changed slightly without drastically changing its meaning. In a genome, all the information for a cell must be present, and if any is missing, say goodbye to life or good health. Moreover, the information itself must exist alongside already existing biomolecules to express and transcribe the information. Proteins transcribe DNA to create mRNA, mRNA codes for the production of proteins. Moreover, DNA is produced by an enzyme, but it itself contains the information to create the enzymes. The production of RNA polymerase from DNA that codes for RNA polymerase requires the action of RNA polymerase. The DNA that codes for RNA polymerase cannot be reproduced without replication proteins, but replication proteins are only made by DNA, with the action of RNA polymerase. The entire system is interdependent and irreducibly complex.
Decision/Choice Reflection
Different organisms use and employ different molecular machinery that is tailored and specified to fit perfectly with that organism. Not all flagella are the same across all bacteria. Moreover, different body plans of an animal (endoskeleton, or exoskeleton) require a completely different set of genetic code to produce the structures. Moreover, certain molecules exhibit different linkages and formations in different types of organisms. A good example is the ester and ether linkages of the tails of phospholipids between Archaea, Bacteria, and Prokaryotes. This means their genetic coding for the biological synthesis of these molecules is different. The fact that different organisms show different code and characteristics is best explained by an intelligent designer's choice, rather than the unexplained common ancestry that is so commonly claimed.
Conclusion
If you have made it to the end of the article, good freaking job man! That was a lengthy read and a lot of information, but I pray that your understanding of Abiogenesis and biological origins has cleared up. And if you are still unconvinced, that is okay. All that I want you to know is that you believe what you believe not on evidence and empirical observations, but rather a blind faith in a naturalistic materialist worldview. Many will try to say that DNA is inherently information-bearing, which hinders the challenge of who inputs the information. This is a misunderstanding of DNA's nature. Researchers have made lines of DNA that are completely useless (I am speaking of the watermarks implanted into the Synthia genome that will be discussed in a future article). With experiments conducted that create useless strands of DNA, we can conclude that DNA is not inherently information-forming, as some believe.
The complexity of the genome, the molecular machinery it creates, the interdependency of the genome and the cells systems, the low chances of random formation, the lack of necessity in chemistry and physics, the design characteristics of DNA and life, the high-level information nature, and the low confidence of the Abiogenesis community all point towards to sobering conclusion: There was an intelligent mind that played a role in the creation of life on this planet. Atheistic Abiogenesis has been Debunked, and my prayer is that you can open the Word and hear His voice speaking as you read, and that you can come to know the one and only designer God, Jesus Christ.


Comments